Enhance Your Prompting Skills with Fabric: Optimizing AI Usage
Fabric by Daniel Miessler is a project aimed at leveraging AI for everyday tasks.
To maximize the potential of Generative AI tools, it’s essential to understand effective prompting techniques. A good starting point is the Deep Learning short course: ChatGPT Prompt Engineering for Developers
This will ensure that you receive the desired outputs in the format you’ve configured.
Fabric by Daniel Miessler takes it to a greater level with effective and intelligent system prompts, ensuring ease of use for any imaginable use case.
Fabric is easy to set up with the instruction provided in the project. I chose to use Kali Linux as I plan to integrate it into my pentesting workflow.
Installation
Highlighting the installation process:
Clone the repository
git clone https://github.com/danielmiessler/fabric.gitEnter the project folder
cd fabricEnsure the setup file is executable.
chmod +x setup.shInstall poetry
curl -sSL https://install.python-poetry.org | python3 -Run the setup script
./setup.shTo setup and use fabric you will need a OpenAI account and API key. Create the openAI account for free and login to the platform.
Navigate to API Key sectiona and generate the New secret Key.
https://platform.openai.com/api-keys
Now run following command and enter the API Key.
fabric --setupAccess OpenAI’s GPT models using APIs involves some cost. And the pricing depends on the model you select.
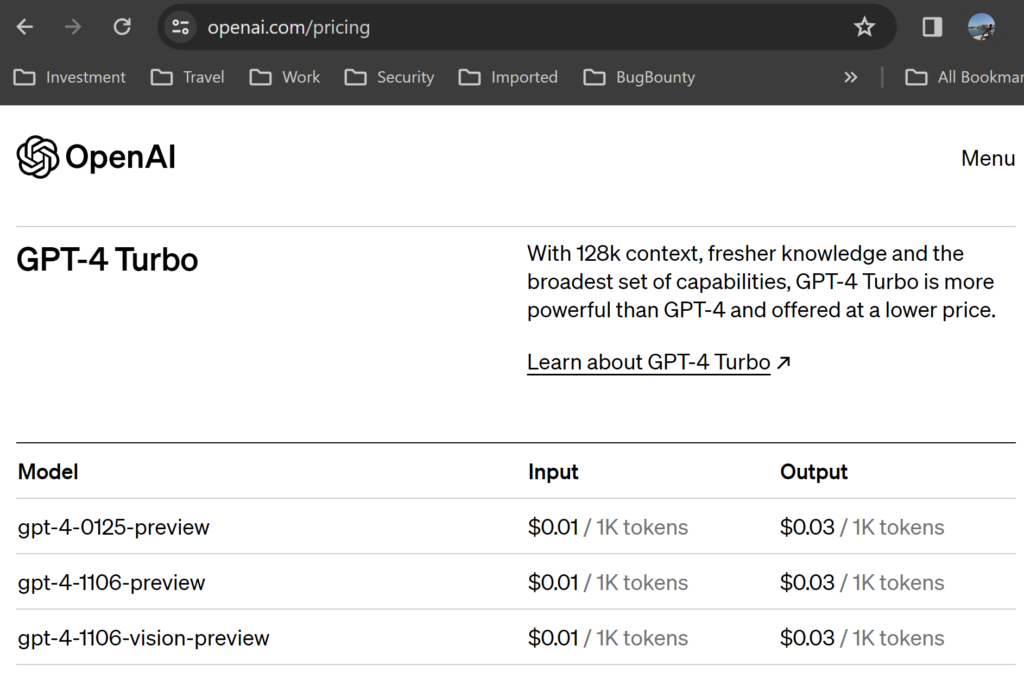
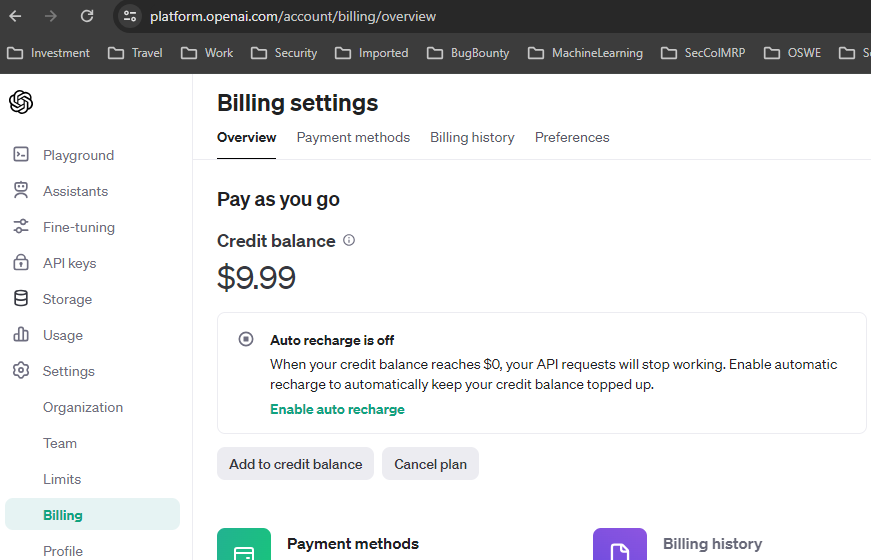
You can start with free credits that you get or you can add $5 to start using APIs
Now you can check the avaiable models using following command:
fabric --listmodels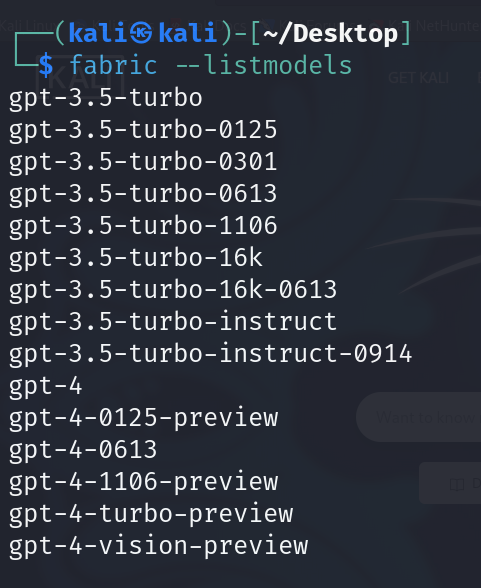
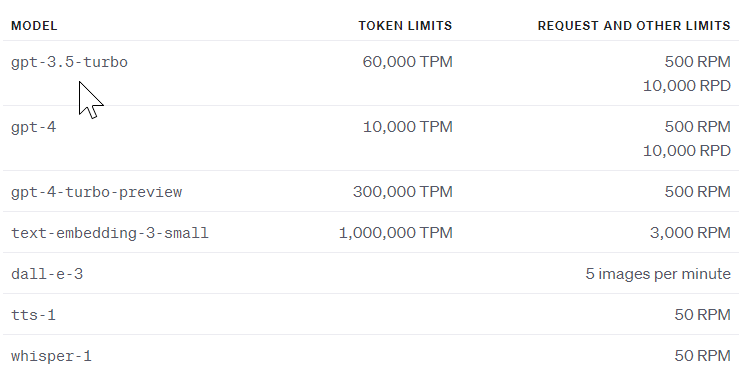
Token Limit
Large language models process text as tokens, which are common sequences of characters found in a set of text.
A token limit typically refers to the maximum number of tokens (words, punctuation marks, etc.) that can be input into the model for processing at one time. Exceeding the token limit may result in errors or the truncation of input beyond the specified limit by a model.
Here are the token limits for specific models and their corresponding usage limitations:
You can check for the token lenght using OpenAI’s tokenizer.
Demo
I’m a huge fan of the Critical Thinking Bug Bounty Podcast. Hosted by Justin and Joel, the podcast features interviews with experts in the field covering various bug bounty topics. Every episode leaves me reaching for a notepad to jot down new ideas and concepts.
I utilized Fabric’s extract wisdom pattern to gather all the notes from YouTube transcriptions.
To achieve this, I employed https://youtubetranscript.com/ to obtain the transcription of one of the episodes and then compiled it into a text file.
You can refer the pattern here: https://github.com/danielmiessler/fabric/blob/main/patterns/extract_wisdom/system.md
The ‘extract summary’ pattern captures the essence of the episode, highlighting surprising and insightful ideas, facts, quotes, and references. It closely resembles what I would typically note down but in a more elegant manner. The genius behind the pattern’s structure is truly commendable.
After obtaining the transcript, you can simply feed it into the ‘extract_wisdom’ pattern and choose a model. For cost-saving purposes during the trial run, I opted for the GPT-3.5-turbo model.
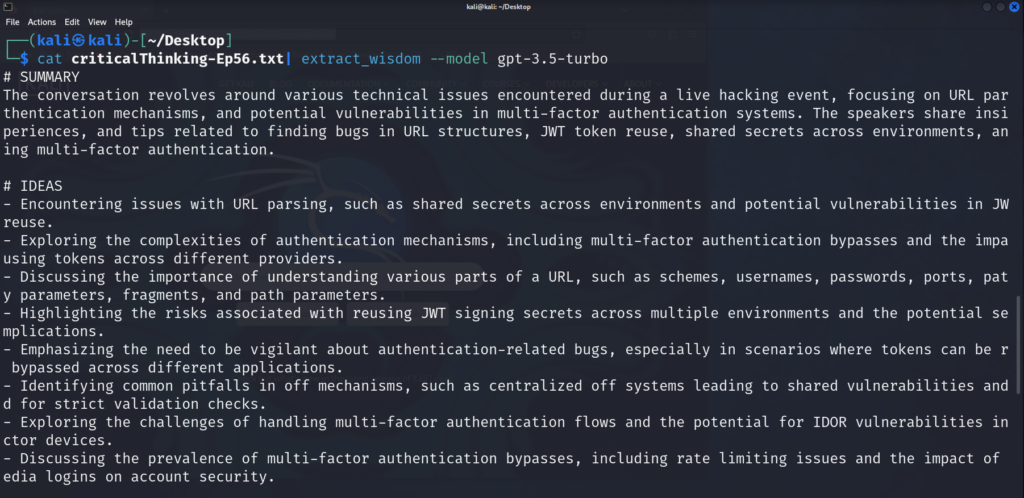
Even with this model, the results are precise and provide excellent insights.
The reference section provides further resources for gaining a deeper understanding of the subject.

With transcription inputs of 15K tokens and response tokens totaling around 800, the cost is approximately $0.01.
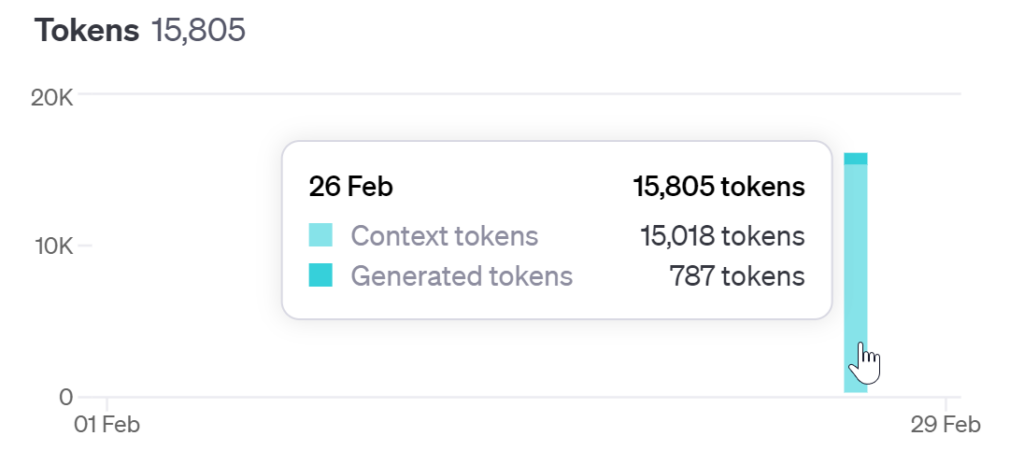
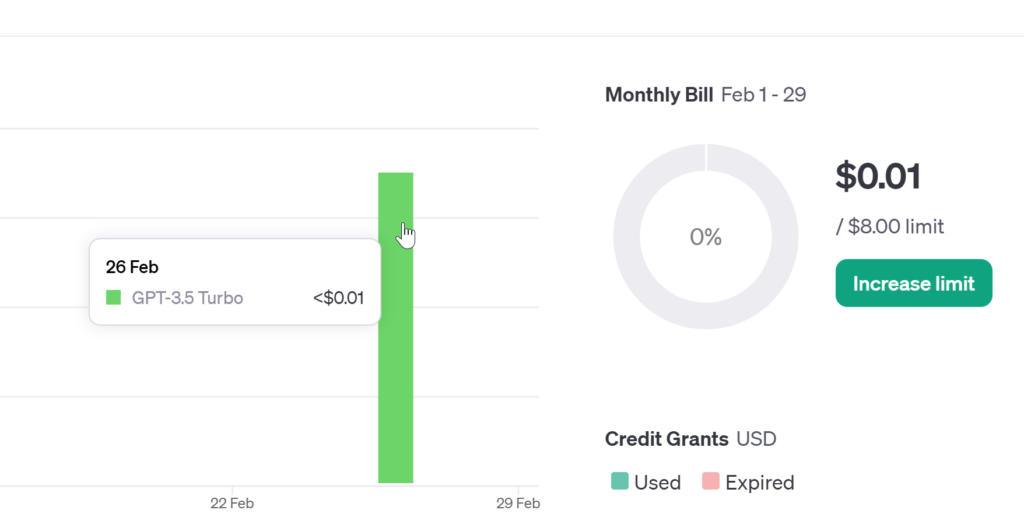
I’m currently working on setting up the clipboard commands and integrating the YouTube transcription library (youtube-transcript-api) in Python to make the operations more seamless.

- Tousif
Application security Engineer, Husband, Father
- Enhance Your Prompting Skills with Fabric: Optimizing AI Usage February 29, 2024
- Building Home Lab for Pentest [Vulnerable AD Server] – Part 2 January 8, 2024
- Building Home Lab for Pentest - Part 1 January 5, 2024
- Active Directory for Pentest – Part 1 December 24, 2023
- Automating Pentest workflow – Using simple python script September 24, 2023